Esta es la entrada en la que se mostrara el proyecto final el cual consiste en realizar una aplicacion de google o una aplicación de facebook.En nuestro caso escogimos la aplicación de facebook.
(para que funcione es necesario estar en tu cuenta de facebook)
NOMBRE: Alarma con Reloj
OBJETIVO: Una aplicación sencilla pero muy útil para los que adictos al facebook que por pasar tanto tiempo ahí pierden la noción del tiempo, una alarma te recordaría eventos importantes a realizar a una hora especifica.
DESARROLLO DE APLICACIÓN: Lo primero que tuvimos que hacer es seguir los pasos del tutorial que se encuentra en este blogposteriormente tuvimos que registrarnos aquí link para que podamos acceder a nuestro
servidor lugar donde crearemos 2 subdominios uno para subir todos los archivos php que son necesarios para que nuestra aplicación de facebook pueda funcionar, además que agregamos un índex con el siguiente código.
(para que funcione es necesario estar en tu cuenta de facebook)
donde lo siguiente lo modificamos como ya fue mencionado en el tutorial con los datos que nos da al crear la aplicación
$appapikey = '111061448960918';
$appsecret = '7ab20877a65173d6087bc24904e8a984';
posteriormente en el otro subdominio se sube la aplicación que en nuestro caso es un reloj flash, y modificamos el índex para que podamos direccionar nuestro índex a ese subdominio y agregamos al final el nombre de la aplicación junto con la extensión ya solo es cuestión de ir a la dirección url de nuestra aplicació
n para que podamos ver los cambios y se vea la aplicación flash directamente en nuestro facebook.
TIEMPO DE EJECUCIÓN:
Como se ve esta aplicación es una alarma , se selecciona la hora los minutos y los segundos en que desees que suene y manda una señal de sonido típico de las alarmas comunes.
Cuenta con 3 tipos de sonido de alarma asi como horas, minutos y segundos de uso facil y comodo para cualquier usuario que requiera usarla:
INTEGRANTES:
1455422 Daniel Iván Martínez Covarrubias.
1535320 Mario Salinas Lopez.
1535212 Roberto Valenzuela Padilla.
1463939 Hazael Ugarte Rubio
1447941 Laura Estefania Fierro Galvez
Favor de dejar comentarios al respecto, gracias y saludos.
Pueden descargar la carpeta con todos los archivos aqui (estan en .tar.gz)
Crear una aplicación de Facebookpor primera vez puede suponer un buen dolor de cabeza, aunque la plataforma tiene muchos tutoriales no son todo lo detallados que deberían en muchos casos o en otros están en inglés o en español mal traducido. A continuación voy a contar paso a paso como crear nuestra primera aplicación de prueba para Facebook en un entorno PHP .
Cómo requisitos imprescindibles para comprender este tutorial debes tener un nivel medio de desarrollo con PHP, un servidor web apache que soporte PHP5, tener mucha experiencia como usuario de aplicaciones Facebook y mucha, mucha paciencia
Pasos
1. Accede a Facebook con tu usuario y tu clave. 2. Ve a la url http://www.facebook.com/developers. Se te solicitará permiso para aceptar esta aplicación.
3. A continuación entraremos en una página que nos dará la opción de crear una nueva aplicación y de descargarnos las librerías PHP necesarias para nuestro servidor.
4. Descargamos en primer lugar las librerías PHP, incluyen una aplicación de ejemplo.
5. Ahora hay que instalar las librerías en nuestro servidor subiéndolas mediante FTP, recuerda que son librerías para PHP5 por lo que nuestro servidor debe soportar este lenguaje. Hay servidores que aungue soportan PHP5 tienes por defecto activado PHP$, puedes activar PHP5
6. Una vez subimos hemos subido las librerías y la aplicación de pruebas a nuestro servidor tenemos que volver a Facebook y hacer click sobre “Configurar una nueva aplicación” o “crear una”.
7. A continuación se nos pide que demos nombre a la aplicación y que aceptemos las condiciones de servicio. Puedes poner el nombre que quieras, aunque sea similar a una aplicación ya existente.
8. Una vez le hemos dado al botón de “Guardar cambios” nos econtramos con la pantalla de configuración básica de nuestra aplicación. Vamos a destacar en primer lugar de la misma 3 datos que son importantísimos: Aplication ID, Clave API y secreto, debemos tomar nota de estos datos (aunque siempre estarán disponibles sin entramos con nuestro usuario en la página de los desarrolladores).
9. A continuación se nos pide que introduzcamos los datos de información básica: descripción, icono de la aplicación (el icono pequeñito), logotipo de la aplicación ( el icono grande), el idioma y los desarrolladores (esta parte da lugar a uno de los agujeros más curiosos que tiene Facebook a día de hoy, le dedicaré en su momento un post).
10. Nos quedaría confirmar la información del email del desarrollador y las Urls de ayuda, condiciones de uso y privacidad. No hace falta que tengas esas páginas creadas, puedes poner las urls que vayas a crear en el futuro.
11. Le damos al botón “Guardar cambios” y Facebook nos envía a la página de inicio para desarrolladores de nuestra nueva aplicación. Buscamos el botón de “Editar configuración” y lo pulsamos. 12. Volvemos a la página anterior de creación de la aplicación, pero ahora debemos hacer click en la pestaña “Lienzo”. 13. Esta pantalla es importantísima, en ella debemos en primer lugar configurar la url de nuestra aplicación en Facebook.
14. A continuación debemos configurar la url de la aplicación en nuestro servidor PHP (es de aquí de donde Facebook leerá las respuestas de nuestro servidor para publicarlas en su entorno). En concreto en este ejemplo deberemos poner la url de nuestro servidor que nos lleva a la aplicación “footprints” de ejemplo que hemos subido antes por FTP.
15. Para este tutorial debemos dejar configurada la aplicación en modo FBML, no en modo Iframe. 16. Una vez hecho esto guardamos los cambios y nos vamos a nuestro servidor PHP. Dentro de la carpeta footprints hay un fichero llamado config.php, debemos editarlo y darle valor a las variables $api_key con nuestra CLAVE_API y $secret con nuestra clave secreta SECRETO. Esta aplicación de muestra requiere para funcionar interactuar con una base de datos de nuestro servidor así que debes configurar los datos del servidor de base de datos y crear la tabla que pide. Esta parte viene con comentarios PHP. Y ¡Listo! Suertee(:
Ahora sólo nos queda ya compararla con el funcionamiento de la nuestra con nuestra url de facebook, es decir, http://apps.facebook.com/[nombre dado en el paso 13]
Google Apps es uno de los ya variados servicios que el gigante Google nos ofrece. Por supuesto, como la mayoría de sus aplicaciones, completamente gratis; aunque también existe una versión de pago especialmente diseñada para clientes empresariales y grandes organizaciones multinacionales.
Google Apps ofrece herramientas eficaces para la manipulación, gestión y personalización de utilidades para dominios o nombres de Internet. Es decir, Google Apps te permite gestionar el correo electrónico de tu dominio (a través de Gmail), mensajería instantánea entre miembros de tu organización o red (Google Talk), calendario en línea (Google Calendar), edición de Documentos también en línea (Google Docs) y creación de sitios web profesionales (Google Sites).
Google Apps ofrece tres planes distintos de servicio, enfocados precisamente a tres principales tipos de clientes. Asímismo, dentro de cada plan se ofrecen diferentes escalas del servicio:
Empresas y empleados. Estándar (Gratuita) y Premier ( de Pago).
Centros Docentes y Estudiantes. Estándar (Gratuita), Premier (de Pago) y Educación (Sólo para instituciones estudiantiles sin ánimo de lucro).
Organizaciones y Miembros. Mismos planes que la Edción de Centros Docentes y Estudiantiles.
Una de las mejoras que se han integrado recientemente a Google Apps, son las novedosas herramientas de Seguridad de Postini, empresa que Google adquirió en el año 2007. Esta tecnología incluye una gestión centralizada de la política de los mensajes salientes y entrantes, así como para los filtros anti-spam; bloqueo de correos electrónicos que intenten enviar o difundir información sensible de tu empresa u organización; así como un novedoso y potente anti-virus web completamente personalizable según el grado de tus necesidades.
Algunas ventajas (si, más) de Google Apps:
Capacidad de hasta 7 GB para correo electrónico, y sigue creciendo (similar a Gmail).
Interfaz web personalizable.
POP3 para descargar e-mail hacia Microsoft Outlook, Apple Mail, Thunderbirdo cualquier gestor de correo electrónico.
A partirde este año, totalmente en español.
Cuenta catch all, o cuenta que recibe todo el correo perdido enviado a su dominio
Acceso IMAP para sincronización del correo desde diferentes dispositivos móviles.
Facebook Apps
Detrás de los tres pilares “integración profunda”, “distribución masiva” y “nuevas oportunidades”, la red social Facebook ofrece una completa API para que los desarrolladores aprovechen al máximo las virtudes inherentes de una red social.
Facebook logró su popularidad siendo una red social capaz de contener aplicaciones realizadas por terceros, permitiendo así la realización de negocios a partir de la misma. Más allá de las aplicaciones propias que presenta, como es el caso de: “The Wall”.
Suerte de pizarra virtual del usuario donde otros usuarios pueden dejarle mensajes o “Status”, que permite a los usuarios indicar sus actividades o estados de ánimo al resto de la red, Facebook permite la creación de aplicaciones mediante la utilización de web services para el acceso a los datos de la red.
Creando aplicaciones en Facebook
Los recursos disponibles a los desarrolladores se agrupan en 3 categorías:
API: es una interfaz basada en REST que permite el acceso a los datos del perfil, amigos, fotos y eventos del usuario mediante la utilización de mensajes GET o POST.
Consultas (FQL, “Facebook Query Language”): es un lenguaje de consultas similar a SQL utilizado para acceder a los mismos datos que la API pero permitiendo consultas más complejas.
Maquetación (FBML, “Faceboook Markup Language”): es un lenguaje de markup similar a HTML que permite ser intercalado con el HTML a utilizar para integrar las aplicaciones a la experiencia de usuario Facebook. Utilizando FBML se pueden acceder distintos puntos de la red como ser el perfil, acciones del perfil, canvas y feeds. Este lenguaje también incluye soporte para AJAX y Javascript.
Anatomía de una aplicación en Facebook
Una aplicación en Facebook posee una compleja estructura que permite brindar una experiencia de usuario completa:
Product Directory: cuando un usuario navega el directorio de aplicaciones de Facebook, por cada aplicación se muestra una pequeña sección con el nombre, una imagen y una pequeña descripción.
About: esta página muestra información general de la aplicación. Debe inducir al usuario a instalar la aplicación.
Left Nav: es el panel de navegación izquierdo. Las aplicaciones pueden tener su ícono y nombre en este panel.
Canvas Page: es la página principal de la aplicación. Home: esta página es accedida utilizando el panel de navegación de la izquierda, en general muestra información de los amigos del usuario. User Dashboard: es la página donde el usuario administra sus datos en una aplicación y determina de que forma las aplicaciones acceden a sus datos personales.
Profile: es la representación online de la identidad del usuario. La API provee múltiples puntos de integración con el perfil del usuario permitiendo actualizar datos del mismo. Profile Box: presenta información actualizada sobre las acciones recientes del usuario. Profile Actions Links: debajo de la foto del usuario en el perfil, se pueden agregar enlaces para invocar acciones en la aplicación.
Privacy Settings: se utiliza para definir los niveles de privacidad de los datos del perfil por aplicación.
News Feed: como su nombre lo indica es un “feed” de noticias, allí las aplicaciones pueden “publicar” información del usuario de la misma.
Alerts: las aplicaciones pueden enviar notificaciones a los usuarios a través del correo electrónico.
Message Attachments: las aplicaciones pueden incluir archivos adjuntos que aparecen en la ventana para componer mensajes.
Requests: las aplicaciones pueden crear peticiones que aparecen en la parte superior izquierda de la página principal. En general son iniciados por amigos que solicitan realizar alguna acción.
CGI (Common Gateway Interface) es una interfaz entre aplicaciones externas y servicios de información.
Un documento HTML, es algo estático, permanente, lo que no se adecúa a las necesidades de interactividad, acceso a información en constante actualización, consulta a bases de datos o seguimiento, control o recuperación de resultados de un determinado proceso. Por ello, a veces es necesario acceder a una información que se está generando "en tiempo real". Así pues, es necesario contar con algún tipo de pasarela como la que define CGI.
La interfaz define una forma cómoda y simple de ejecutar programas que se encuentran en la máquina en la que se aloja el servidor. Para el cliente presenta una ventaja en el aspecto de la seguridad, ya que no tendrá que ejecutar ningún programa de efectos desconocidos en su sistema local. Además de eliminar la necesidad de aprendizaje, se resuelven los problemas de mantenimiento, operación y distribución de clientes ya que el acceso se realizará a través de cualquier cliente estándar de WWW y la comunicación se realizará según el protocolo HTTP.
Será necesario tener en cuenta algunos aspectos sobre seguridad, ya que tener un programa CGI equivale a que "TODO EL MUNDO podrá ejecutar un programa en MI sistema". Esto se solventa incluyendo los programas CGI en un directorio determinado, denominado generalmente cgi-bin, directorio que no suele ser accesible a todos los usuarios. Cuando un servidor de WWW recibe como petición un documento alojado en este directorio, entenderá que se trata de un programa ejecutable.
Pero CGI plantea como inconveniente la necesidad de ejecutar programas en el servidor, de los cuales es necesario tener una copia por cliente ya que no permite hacer uso de recursos compartidos y, al tratarse de una pasarela, no es posible disponer de un control directo de la comunicación. Por ello se plantean nuevas alternativas, como el NSAPI de Netscape Corporation y, por supuesto, Java.
LENGUAJES DE PROGRAMACIÓN CGI
CGI, como la propia palabra indica es una interfaz entre servidores de información y programas de aplicación. Por tanto, define una serie de reglas que deben cumplir tanto las aplicaciones como los servidores para hacer posible la presentación de resultados de programas ejecutables en tiempo real a través de servicios de información estandarizados. Por ello, se habla de gateway o pasarela entre una y otra dimensión. Al tratarse de una interfaz, no existe ningún tipo de dependencia con el lenguaje de programación empleado.
En principio, cualquier lenguaje es susceptible de ser utilizado para desarrollar programas CGI, ya sea interpretado o compilado. En "la red" existen aplicaciones CGI desarrolladas en C, C++, Fortran, Perl, Tcl, Visual Basic, AppleScript y cualquier shell de UNIX. Los lenguajes interpretados como sh, tcl y, sobre todo, perl, tienen mayor facilidad de mantenimiento y depuración. Otra ventaja es que, por lo general, suelen ser de más alto nivel, con lo que no permiten realizar ciertas maniobras con la memoria y es más difícil dejar procesos sueltos descontrolados en el sistema. Uno de los lenguajes más utilizados es el Perl que, siendo interpretado, proporciona una potencia similar a la de C con una sintaxis muy parecida.
La contrapartida es que un lenguaje compilado es siempre mucho más rápido que uno interpretado. En el caso de CGI la velocidad de ejecución es importante, ya que habrá que sumar el tiempo de ejecución a la latencia de red y a la velocidad de transmisión, tiempos de espera que tendrá que sufrir el usuario del cliente.
Un gestor de base de datos o sistema de gesti´on de base de datos (SGBD o DBMS) es un software que permite introducir, organizar y recuperar la informaci ´on de las bases de datos; en definitiva, administrarlas. Existen distintos tipos de gestores de bases de datos: relacional, jer´arquico, red, ... El modelo relacional es el utilizado por casi todos los gestores de bases de datos para PC´s. El modelo relacional (SGBDR) es un software que almacena los datos en forma de tablas El problema: Sistemas de ficheros Tradicionalmente, los datos se han organizado en ficheros. Un fichero mantiene informacion homogenea, dispuesta en registros. Ej.: Empleados, Clientes, Nominas, etc. Diferentes programas pueden mantener diferentes ficheros referidos a la misma entidad Estos sistemas presentan algunos problemas:
Redundancia: Normalmente es perjudicial ya que da lugar a inconsistencia, cuando un dato no se actualiza en todos los lugares donde aparece. Es el caso de datos repetidos, que aparecen en varios ficheros, o de datos calculados, que podrıan obtenerse a partir de otros datos. Rigidez de busqueda: A cada fichero, segun la manera en que mas frecuentemente se accede a el, se le da una organizacion. Si despues se necesita otro tipo de acceso, puede resultar lento trabajar con el fichero. Dependencia de los programas: La informacion de donde comienza un campo, donde acaba, su tipo, etc. esta controlada por el programa; cualquier cambio en la estructura del fichero implicar´a una modificacion de los programas. Problemas de confidencialidad y seguridad: La confidencialidad consiste en evitar la consulta de ciertos datos a determinados usuarios mientras que el control de seguridad de los datos almacenados impedira que puedan ser modificados por personas no autorizadas. La solucion: Bases de datos Es la alternativa que aborda la solucion a estos problemas. Se trata de dar una solucion integral al almacenamiento y gestion de los datos, en lugar de soluciones parciales : • Evitar la redundancia ”gratuita” • Flexibilidad de busqueda • Independencia de los programas • Seguridad y confidencialidad integral
LOS USUARIOS Hay tres clases de usuarios: • Usuario final: Accede a la base de datos desde su PC empleando un lenguaje de consulta (DML) o a traves de un programa. – Son usuarios que no necesitan formacion tecnica – Podran manejar la informaci´on de forma sencilla y eficiente a traves de la interfaz que se les proporcione. • Administrador de la base de datos: Se encarga del control general del sistema de base de datos. Usualmente actua como intermediario entre programador y usuario final. – Son los responsables de su seguridad e integridad – Requieren un amplio conocimiento de la herramienta SGBD a nivel de administracion: tablas, ındices, consultas, formularios, informes, macros, etc. • Programador de aplicaciones: Encargado de escribir programas de aplicaci on que utilicen bases de datos (lenguaje de alto nivel, como Cobol, Clipper, VisualBasic, 4GL). – Pueden utilizar lenguajes de alto nivel para acceder y actualizar los datos. – Son capaces de implementar soluciones a medida. – Su conocimiento de la herramienta SGBD debe ser aun mas profundo: modulos, API (application programa interface), etc. CONCEPTOS DE BASES DE DATOS Entidades Una entidad es una clase o categorıa de objetos que poseen caracterısticas diferenciadoras que los distinguen del resto. Ejemplo: Dentro de una empresa que vende complementos para el automovil encontraremos las siguientes entidades: Artıculos, Clientes, Proveedores, Pedidos, etc. Otros ejemplos: En una biblioteca: Libro, Socio, Autor, etc. En una academia: Alumno, Profesor, Cursos, Asignaturas, etc. En concesionario de automoviles: Vendedor, Cliente, Automovil, Pedido, etc. Las entidades consideradas en una base de datos deberan determinarse en consonancia con las necesidades. Por ejemplo, en una empresa de transportes aparecen diferentes entidades: vehıculos, mercancıas, transportistas, clientes, etc. No obstante, si nuestro objetivo fuere diseñar una base de datos para el control de las inspecciones tecnicas de los vehıculos, entonces el resto de entidades (mercancıas, transportistas, clientes, etc.) no seran tenidas en cuenta. Cada objeto perteneciente a una entidad debe poseer informacion suficiente para que pueda ser identificado de forma unica. Atributos Toda entidad contiene un conjunto de datos, a los que llamaremos atributos o campos, que permiten describir de una manera completa y unica a cada elemento de la entidad. Ejemplos: Entidad ”Clientes”. Atributos: Codigo, DNI, Nombre y apellidos, Direccion, Tel´efono, Cuenta bancaria, etc. Entidad ”Productos”. Atributos: Codigo, Descripcion, Fabricante, Color, Peso, Precio, etc. Cada atributo se corresponde, en una base de datos relacional, con las columnas o campos de una tabla. En una base de datos relacional, las entidades se representan en forma de tablas. Registros Para una entidad dada, cada entrada o aparicion (cada cliente en la entidad Clientes, cada vehıculo en la entidad Vehıculos, etc.) se denomina registro u ocurrencia de registro. Un registro es, por tanto, una representacion de un objeto perteneciente a una entidad dada. En una base de datos relacional, los registros se corresponden con las filas de las tablas. Ejemplos: La entidad Automovil con los campos N matricula, Marca, Modelo, Color, Km, Gasolina, y un registro (o ocurrencia de registro): J-5757-M, Ford, Orion, Rojo, 45401, Super.
Todos los usamos para todo lo que se haga en Internet, sin ellos no iríamos más allá de un puñado de páginas que nuestra mente pueda retener en el cerebro, sin los buscadores sería casi imposible encontrar en estos días una información precisa acerca de cualquier tema, simplemente regresaríamos a las enciclopedias. Pero, ¿qué son los buscadores? ¿Cómo funcionan?
Según las estadísticas, en Internet el 85% del tráfico que se tiene es a través de los buscadores, eso quiere decir que el 85% del uso de Internet se hace a través de búsquedas, de personas que no saben exactamente a donde dirigirse y gracias a los buscadores desembarcan en una página web que les puede ser de ayuda o no.
Estoy casi segura de que alguna vez has usado un buscador, tal vez no los conozcas precisamente por su nombre genérico, pero si por sus nombres específicos, entre los más conocidos están: Google, Yahoo!, MSN, Ask, Aol, Altavista, etc.
Según las cifras estadísticas de Nielsen NetRatings del año 2008, el empleo de los buscadores genéricos en los Estados Unidos es el siguiente: 53.6% para Google, 19.9 para Yahoo!, y 12.9% para MSN. Esto obviamente cambia para ciertos países en donde Google arrasa con los demás buscadores.
Un buscador funciona de una manera simple basándose en 3 componentes fundamentales que se interrelacionan para entregarle al usuario una lista de resultados que es la que ve sólo microsegundos después de haber realizado sus búsqueda.
En primer lugar tenemos una araña o robot, que en esencia es una navegador autómata que va por todo el ciberespacio viendo cada una de las páginas web, analizando en su trayecto su código fuente (HTML), así como todo el texto que hay en el contenido de la página incluyéndolo inmediatamente a la base de datos ya sea porque es una página web nueva o es una página web antigua que tiene contenido nuevo y actualizado.
En segundo lugar tenemos la base de datos. Este sistema de almacenamiento guarda registro de toda la información de cada una de las páginas web que la araña le ha enviado. Cuando una persona hace click en el botón buscar, inmediatamente la base de datos se pone a trabajar para mostrarle a usted la información más relevante conforme a su búsqueda.
Y en tercer lugar, la parte humana la proporciona un algoritmo de relevancia o proceso de emparejamiento que ordena los resultados basándose en una serie de variables para encontrar aquellas que valen más la pena de mostrar primeras que otras.
De esta manera sencilla funcionan los buscadores y los procesos cada vez son más y más simples y rápidos en beneficio del usuario.
Con esta sección dedicada al PageRank entramos en los factores off the page, es decir, aquellos exteriores a nuestra propia web, y por tanto sobre los que no tendremos un control tan directo como en lo que es puramente la optimización.
Google fue revolucionario precisamente porque fue el primer gran buscador que valoró estos elementos; los aspectos que estaban al alcance de los autores de las webs eran manipulados porque eran manipulables; así pues, el desarrollo de un buscador que funcionara bien se debía basar en aquellos aspectos que se estuvieran más alejados de la influencia de los webmasters.
PageRank para Dummies
El PageRank se ha convertido en un concepto casi mítico entre los webmasters, que no paran de hacer preguntas acerca de él. Así pues, para esta sección contaré con la ayuda de uno de esos webmasters, John Dummies, que hará las preguntas que previsiblemente también se os ocurrirán a vosotros.
El PageRank (bautizado así en honor de uno de los fundadores de Google, Larry Page) ha sido considerado el corazón del sistema de Google para medir la relevancia de las webs. Hay quien cree que el PageRank es el factor clave para lograr buenos puestos en Google, y hay quien dice que el PageRank apenas sirve de nada.
Un símil muy socorrido para explicar el PageRank es que es como un sistema de votaciones. Si yo tengo una web A y en una de mis páginas pongo un link hacia la página de la web B, estoy 'votando' a esa página; estoy indicando que es un recurso de interés.
Así, cuantos más links reciba una página, mayor será su PageRank (PR para los amigos).
No necesariamente. Porque el PR transmitido no es un valor absoluto. A su vez, depende de:
El PR que tenga la página que nos enlaza
El número de links salientes que tenga esa página
Digamos que a la página A le apunta la página B. Digamos que la página B tiene 20 puntos de PR. Y digamos que la página B también tiene un enlace hacia la página C.
Por tanto, lo primero que debemos tener en cuenta es que, si tiene dos links, el PR transmitido se dividirá entre ellos.
No es seguro que el PR transmitido por una página se divida por igual entre todos sus enlaces, pero en esta explicación asumiremos que es así para no complicarla innecesariamente.
El PR de la página que lo transmite tampoco llega tal cual a su destino; Google aplica un factor de debilitación: multiplica el PR transmitido por un número menor a 1 (en la fórmula original, 0'85).
Es decir, que la página A recibirá 8'5 puntos de PR.
¡No! Aunque no comozcamos la fórmula actual del PR, sí conocemos la fórmula original de los primeros trabajos sobre Google. Aquí os presento la fórmula original del PR (hay otra variante, pero esta es más simple y nos permitirá entender claramente cómo funciona el PR):
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn))
PR(A) es el PageRank de la página que tomamos como referencia.
d es el factor de debilitación.
(1-d) asegura que cualquier página indexada por Google, aunque no reciba ningún enlace, tendrá un PR mínimo de 0'15.
PR(T1)/C(T1) será el PageRank (PR) de una de las páginas que nos enlaza, (T1), dividido por todos los enlaces (C) que también salen de esa página T1, es decir, el PR que nos transmite.
... + PR(Tn)/C(Tn) lo mismo que el punto anterior, repetido por cada página que nos enlace.
Para empezar, la fórmula del PR seguramente ha sufrido variaciones, y actualmente debe presentar diferencias respecto a la que he puesto aquí. Sin embargo, sigue siendo una buena guía para saber cómo se comporta el PR en líneas generales. Además, para conocer tu PR deberías conocer exactamente el PR de las páginas que te enlazan. Y para conocer el PR de las páginas que te enlazan deberías conocer exactamente el PR de las páginas que a su vez las enlazan. Y para conocer el PR de las páginas que enlazan a las páginas que te enlazan, deberías conocer...
Afortunadamente, puedes tener una aproximación descargando e instalando en tu navegador Explorer la barra de herramientas de Google en http://toolbar.google.com/.
Hacia la mitad de la barra verás un raya en verde y blanco. Es una representación gráfica del PR de la página en la que estás, representada en una escala del 1 al 10.
De hecho, es una aproximación al verdadero PR, pues mientras el PR tiene una escala lineal, la barra de Google lo presenta en una escala logarítmica. Esta es una hipótesis acerca de la relación entre el verdadero PR y el PR representado en la barra de Google extraída del artículo PageRank Uncovered:
PR verdadero
Barra de Google
De 0.00000001 a 5
1
De 6 a 25
2
De 25 a 125
3
De 126 a 625
4
De 626 a 3125
5
De 3126 a 15625
6
De 15626 a 78125
7
De 78126 a 390625
8
De 390626 a 1953125
9
De 1953126 a infinito
10
Esto explica por qué a los webmasters les cuesta relativamente poco alcanzar un PR3, bastante más un PR4, mucho más un PR5, muchísimo más un PR6, infinitamente más un PR7, etc. El intervalo de enlaces que deben obtener para aumentar un peldaño en el PR que muestra la barra de Google es cada vez mayor. Es cierto que no conviene tener muchos links hacia fuera, pero a menudo este punto de vista se hace desde la falsa creencia de que, puesto que una página transmite PR a las páginas que enlaza, ella está quedándose sin PR. Y eso es un error.
Si la página A tiene 100 puntos de PR y un enlace a la página B, es cierto que le transmite todo el PR que puede transmitir (85, una vez aplicado el factor de debilitamiento), pero eso no quiere decir que se quede sin ese PR. Entonces, ¿a qué viene toda esa psicosis acerca de no tener enlaces hacia otras webs? Lo veremos en Manejar tu PR interno.
El cálculo del PR es un tema complejo, porque el PR de una página determinada A depende del PR de la página que la enlaza, B. Pero si A y B están entrelazadas, ahora el PR de B depende también del PR de A; y si el PR de B ha cambiado, el PR de A, como consecuencia también, etc. Por tanto, Google debe calcular el PR en diversas iteraciones hasta que éste se estabiliza y los cambios sucesivos no provocan cambios posteriores.
Algo muy importante que debes tener en cuenta si quieres tener buen trafico, es que tu sitio debe estar preparado para ser visto por otras personas. O sea, publica el sitio cuando lo tengas bien armado, y no con versiones preeliminares
Es fundamental que tu sitio tenga la descripción del producto/servicio o lo que fuera, dentro de alguna pagina de tu sitio. Aquí deberías incluir las palabras claves que te describan. Ejemplo un sitio de deportes tendrá palabras claves como: “deportes”, los tipos de deportes, noticias mas importantes, nombres de jugadores importantes, etc.
Busca una lista de directorios para hacerte conocer. Esto es, crearte descripciones que se ajusten con tu sitio y subirlas a los directorios.
Ejemplo: Titulo: Deportes – noticias fútbol.
Descripción: Aquí podrás encontrar todas las últimas noticias de fútbol en el mejor portal de deportes. Visítanos y ponte al tanto de todas las noticias del deporte mundial.
Una ves que tengas unas cuantas descripciones hechas, es momento que las empieces a subir a los sitios. Esto es sencillo una vez que lo hayas hecho unas pocas veces. Antes de subirlas, debes buscan dentro del directorio, cual es la categoría que mas se adapta a tu descripción. La cantidad de palabra que puedes incluir tanto en el titulo como en tu descripción varían según el directorio al cual estas subiendo la info. Por lo general poner entre 2 a 8 palabras en el titulo y entre 20 a 80 en la descripción será aceptado por la mayoría.
Algunos directorio gratis son: ver mi archivo de blog: “Lista de Directorios Gratuitos”.
Simple esta la posibilidad de usar directorio pagos, pero te recomiendo que por ahora uses los gratis ya que hay muchísimos por ahí.
Agrega Meta tags a tus paginas.
Los meta tags son importantes para que los robots puedan tener una visión general de que se trata tu pagina. Incluye aquí la descripción general y las palabras claves que te identifican
Otros factores para mejorar tu rankoe de Google.
Densidad:
Una de las cosas importantes que google se fija cuando cataloga las paginas es la densidad de las palabras. Esto significa cuantas veces las palabras se repiten. Aquí hay un aspecto muy importante a destacar: no escribas tus páginas orientadas a los robots, escríbelos orientados hacia el publico. Que sean leíbles y den ganas de terminarlo. Repetir mucho palabras puede dañar gravemente tu rankeo e incluso que se sitio sea prohibido de google.
Google se fija mucho en los primeros párrafos de tus páginas. Mantén a este con información descriptiva de tu sitio.
Nombre de tus páginas.
Todas tus páginas deberían tener un nombre respectivo sobre el contenido específico de cada una de ellas. No dejes el nombre por defecto que los programas de diseño Web puedan darle, usa los title tags para cada una de ellas. Puedes incluir alguna palabra clave en el titulo.
Fotos y flash.
No uses tanto flash o cosas del estilo que puedan endentecer la pagina. Los buscadores tienden a saltearse cuando encuentran código flash. Para tus imágenes puedes usar el alt tag, nómbralas acorde a lo que son. Ganaras que palabras claves que tú elijas puedan estar mas visibles a los buscadores.
Subo esta porque aunque todos lo utilizamos todo el tiempo, nadie conoce a su creador
Larry Page
Lawrence Edward "Larry" Page es un empresario estadounidense. Page es el creador, junto con Sergey Brin,de Google Se estima que tiene un patrimonio neto de más de 17.5 mil millones de dólares.
Google
Durante su doctorado en Stanford conoció a Sergey Brin . Juntos desarrollaron y pusieron en marcha el buscador Google , que empezó a funcionar en 1998 . Google está basado en la tecnología patentada PageRank . Se dice que le pusieron este nombre al buscador por su semajanza con la palabra Googol, que en inglés quiere decir 10 elevado a 100.
Page fue presidente de Google junto con Brin hasta 2001 , año en que decidieron contratar a Eric Schmidt.Page dirige Google junto a Sergey Brin y Schmidt.
Sergey Brin
Sergey Mijaylovich Brin es un empresario estadounidense. Brin es el creador, junto con Larry Page,de Google e estima que tiene un patrimonio neto de más de 17.5 mil millones de dólares.
Google
Brin conoció a Page durante unas jornadas de orientación para nuevos estudiantes en la Universidad de Standford. Aunque inicialmente chocaron, rápidamente conectaron y comenzaron a compartir ideas. Les unía especialmente su interés matemático por la World Wide Web . Fruto de esta unión nacería, en 1996, BackRub, el buscador predecesor de Google. El proyecto creció rápidamente y se dieron cuenta de que habían creado un magnífico motor de búsqueda, que aplicaron a la web con excelentes resultados. Optaron por dejar sus estudios en la Universidad y dedicarse por completo al buscador, solicitando ayudas económicas a profesores, familia y amigos. Compraron servidores y alquilaron un garaje en Menlo Park. La historia de Google Inc . había comenzado.
El Open Directory Project es el directorio editado por personas más extenso y más completo del Web. Su construcción y mantenimiento son realizados por una gran comunidad global de editores voluntarios.
La República del Web
El Web continúa creciendo a un ritmo sin precedentes. Los buscadores automatizados son cada vez menos capaces de entregar resultados útiles a sus usuarios. Los pequeños grupos de editores contratados por los directorios comerciales no pueden mantenerse al día catalogando sitios, y la calidad y cantidad de sus índices se han visto deterioradas. Se están llenando de enlaces muertos, y no pueden mantener el ritmo de crecimiento de Internet.
En vez de luchar contra el crecimiento explosivo de Internet, el Open Directory proporciona los medios para que Internet se organice a sí misma. Conforme Internet crece, crece también el número de personas que la usan. Cada una de estas personas puede organizar una pequeña porción del web y presentarla al resto de la población, filtrando lo malo e inútil y conservando sólo los mejores sitios.
El catálogo definitivo del Web
El Open Directory se basa en los pasos de algunos de los proyectos de cooperación editores / contribuyentes del siglo XX. Así como el Diccionario Oxford de Inglés se convirtió en el referente definitivo con relación a ese idioma por medio del esfuerzo de los voluntarios, el Open Directory sigue sus pasos para convertirse en el catálogo definitivo del Web.
El Open Directory fue fundado en el espíritu del movimiento Open Source y es el único gran directorio que es 100% gratuito. No hay, y nunca habrá, un coste por sugerir un sitio al directorio y/o por usar los datos del mismo. Los datos del Open Directory se ofrecen gratis a cualquiera que cumpla nuestra licencia de uso gratuito.
El cerebro de Internet
El Open Directory es la base de datos sobre contenidos del Web clasificados por personas más extendida. Sus estándares editoriales junto con la aportación de los usuarios de la red proporcionan el cerebro colectivo necesario para el descubrimiento de recursos en el Web. El Open Directory provee de los servicios de directorio esenciales a los mayores y más populares motores de búsqueda y portales, incluyendo Netscape Search, AOL Search, Google, Lycos, HotBot, DirectHit y otros cientos más.
PageRank es una marca registrada y patentada por Google el 9 de enero de 1999 que ampara una familia de algoritmos utilizados para asignar de forma numérica la relevancia de los documentos (o paginas web ) indexados por un motor de busqueda. Sus propiedades son muy discutidas por los expertos en optimización de motores de búsqueda. El sistema PageRank es utilizado por el popular motor de búsqueda Google para ayudarle a determinar la importancia o relevancia de una página. Fue desarrollado por los fundadores de Google, Larry Page y Sergey Brin , en la Universidad de Stanford .
PageRank confía en la naturaleza democrática de la web utilizando su vasta estructura de enlaces como un indicador del valor de una página en concreto. Google interpreta un enlace de una página A a una página B como un voto, de la página A, para la página B. Pero Google mira más allá del volumen de votos, o enlaces que una página recibe; también analiza la página que emite el voto. Los votos emitidos por las páginas consideradas "importantes", es decir con un PageRank elevado, valen más, y ayudan a hacer a otras páginas "importantes". Por lo tanto, el PageRank de una página refleja la importancia de la misma en Internet.
Manipulación
Debido a la importancia comercial que tiene aparecer entre los primeros resultados del buscador, se han diseñado métodos para manipular artificialmente el PageRank de una página. Entre estos métodos hay que destacar el spam, consistente en añadir enlaces a una cierta página web en lugares como blogs, libros de visitas, foros de Internet, etc. con la intención de incrementar el número de enlaces que apuntan a la página.
A principios del 2005 Google implementó un nuevo atributo para hiperenlaces rel="nofollow" como un intento de luchar contra el spam. De esta forma cuando se calcula el peso de una página, no se tienen en cuenta los links que tengan este atributo.
Lo encontre en la web, me intereso y espero les agrade.
Hoy vamos a hablar de una nuevo lenguaje de programación utilizado en Facebook se trata del lanzamiento de HipHop para PHP. Según el ingeniero Haiping Zhao, HipHop les permitió reducir el uso del CPU en sus servidores en un promedio del 50%, dependiendo de la página, resultando en un enorme impacto para todo el sitio de Facebook.
Aunque HipHop se estuvo desarrollándose durante los últimos 2 años, reconocen que todavía no está completo, y la calidad de su código actual puede considerarse como “Beta”. Liberarlo bajo la misma licencia de PHP permitiría a su comunidad completar el trabajo, y al mismo tiempo ofrecer un nuevo enfoque a la hora de escalar sitios muy complejos.
¿Pero qué es exactamente HipHop? Según el mismo Zhao:
“HipHop no es técnicamente un compilador. En su lugar es un transformador de código. HipHop transforma tu código fuente PHP en un altamente optimizado código C++ y luego usa g++ (GNU C++) para compilarlo. HipHop ejecuta el código fuente en una manera semánticamente equivalente y sacrifica algunas características raramente usadas -como eval()- a cambio de una performance mejorada. HipHop incluye el transformador de código, una reimplementación del runtime de PHP y una re-escritura de varias extensiones de PHP comunes para aprovechar estas optimizaciones”.
jueves, 4 de noviembre de 2010
Google lanza una nueva herramienta (App Inventor) que facilita el desarrollo de aplicaciones para Android. El objetivo es que cualquier persona (no solo desarrolladores) sea capaz de crear un app para Android.
¿Cómo funciona Google App Inventor? En modo visual, uniendo una serie de bloques el usuario será capaz de crear aplicaciones totalmente funcionales para Android.
Android Market es (al estilo de la App Store de Apple) el centro de distribución de apps (aplicaciones) para Android. Hasta ahora la principal diferencia es que es un entorno abierto, donde cualquier programador puede distribuir sus creaciones. Al contrario de la App Store, donde se necesita su aprobación para publicar las apps.
Ahora, con Google App Inventor veremos un incremento importante en el número de aplicaciones para Android, ya que es una herramienta que no necesita de grandes conocimientos por parte del desarrollador. Es un arma de doble filo. Por una parte facilita mucho la creación de apps por parte de cualquier usuario. Por contra, es probable que aparezcan muchas aplicaciones de baja calidad.
Personalmente opino que Google App Inventor se puede comparar (hasta cierto punto) con la aparición de los blogs. Parte de los periodistas profesionales se quejaban de que se generaba mucha información de baja calidad. Y es cierto. Pero tambien han aparecido blogs amateurs de gran nivel y con información relevante que todos consultamos practicamente a diario y que se han convertido en una referencia.
Como programador, me parece una herramienta muy interesante. Cualquier herramienta que fomenta la creatividad y hace más sencillo plasmar las ideas en una aplicación real debe ser bienvenida.
¿Va a dejar esto fuera de juego a los desarrolladores de Android? Al contrario. Si un usuario tiene una idea, va a poder crear una aplicación mediante Google App Inventor. Las buenas ideas tendrán cierto éxito y el siguiente paso lógico es mejorar la aplicación. Ahí si será imprescindible un desarrollador profesional.
A largo plazo el resultado será un gran número de apps sin mayor utilidad (basura). Y de entre estas, un grupo de apps novedosas y con éxito que habrán nacido gracias una buena idea que pudo ver la luz mediante App Inventor. Viva la creatividad, viva internet.
En esta entrada pondre una introduccion a lo que es un nuevo lenguaje Ruby, el cual tambien esta relacionado con java, espero les sirva y guste.
Saludos
¿Qué es Ruby?
Ruby es un lenguaje de scripts, multiplataforma, netamente orientado a objetos es software libre, fue creado por Yukihiro Matsumoto conocido como Matz. La primera versión fue liberada en 1995, hereda varias caracaterísticas de lenguajes como: Perl, Smalltalk, Eiffel, Ada y Lisp. Como lo indica su propio autor, es un lenguaje “aparentemente sencillo pero internamente complejo”.
Esto quiere decir que mientras más nos abstraemos en el paradigma orientado a objetos notaremos realmente la complejidad del lenguaje (al menos fue mi caso, ya que vengo de lenguajes estructurados y orientados a eventos); lo considero un lenguaje muy intuitivo casi a un nivel de lenguaje humano.
Ruby fue diseñado para un desarrollo rápido y sencillo. Cada día este lenguaje va ganando más adeptos, tanto así que la empresa Sun Mirosystems, está apoyando un proyecto llamado Jruby que es un interprete de Ruby escrito 100% en Java.
Entre las carecterísticas del lenguaje se encuentran:
Posibilidad de hacer llamadas directamente al sistema operativo.
Muy potente para el manejo de cadenas y expresiones regulares.
No se necesita declarar las variables.
La sintaxis es simple y consistente.
Gestión de memoria automática.
Todo es un objeto.
Métodos Singleton.
un largo.
Muy bien, hasta aquí creo que tenemos una visión básica de lo que es Ruby.
¿Qué es Rails?
Rails es un framework para el desarrollo de aplicaciones web, software libre por naturaleza, está basado en el patrón de diseño Modelo Vista Controlador (MVC). Fue creado por David Heinemeier Hansson, empleado de la empresa 37signals.
Fue liberado por primera vez al público en julio del 2004, y lo implemento en una aplicación orientada a la administración de proyectos llamada Basecamp. Actualmente se uniéron más personas al desarrollo de Rails podemos visualizar aquí a los integrantes. Rails está basado en estos principios de desarrollo:
En esta entrada publicare un ejemplo para que se conozca mejor lo que es una aplicacion en Django. Espero les parezca interesante y en un futuro muy util.Saludos
Estructura de (una aplicación) Django
Django distingue entre proyectos y aplicaciones. Un proyecto es un sitio web completo que constar de una o varias aplicaciones. Estas aplicaciones las proporciona Django o las escribe el desarrollador. El comando que crea un proyecto es django-admin.py. . Simplemente, con django-admin.py startproject miweb se crea un directorio miweb que contiene varios ficheros .py: __init__.py, manage.py, settings.py y urls.py.
__init__.py: Define nuestro directorio como un módulo Python válido.
manage.py: Utilidad para gestionar nuestro proyecto: arrancar servidor de pruebas, sincronizar mod elos, etc.
settings.py: Configuración del proyecto.
urls.py: Gestión de las urls. Este fichero sería el controlador de la aplicación. Mapea las url entrantes a funciones Python definidas en módulos.
Para crear una aplicación nueva dentro del proyecto ejecutamos python manage.py startapp miaplicacion. Este comando crea el directorio miaplicacion y los ficheros __init__.py, views.py, y models.py.
__init__.py: Define nuestro directorio como un módulo Python válido.
models.py: Aquí se definen los modelos u objetos que serán mapeados a una base de datos relacional.
views.py: Define las funciones que van a responder a las urls entrantes.
Esto es un diseño MVC: modelo (models.py), vista (views.py), controlador(urls.py).
Aclaración: los desarrolladores de Django llaman a su arquitectura MVT: Model - View - Template, ya que consideran que el controlador es el propio framework.
Aplicación web: Trivial trivial
Es un Trivial multiusuario..(es un juego de mesa donde el avance está determinado por la habilidad del jugador para contestar pregun tas sobre conocimientos generales)
Especificaciones:
Las preguntas y los usuarios los crea un administrador.
Existen diferentes categorías de preguntas.
Cada usuario tiene su propio juego (esto es, responde a sus preguntas).
Es obligatorio estar validado en el sistema para jugar.
Como es una aplicación de prueba, usaremos el servidor de desarrollo que viene con Django. Los ficheros estáticos (CSS, imágenes, etc) también los servirá Django, Como sistema relacional usaremos sqlite (hay un "driver" para Python).
el planteamiento de Django: el desarrollador define modelos, la herramienta se encarga de traducir estos modelos a SQL, pero hay un inconveniente: si los modelos cambian, hay que hacer el cambio manualmente en el esquema del sistema relacional.
Tras esta breve disquisición, pasemos a definir los modelos. Encontramos las siguientes entidades:
Usuario, caracterizado por un nombre, "login", contraseña, ...
Categoría
Pregunta, con un título, conjunto de respuestas posibles, respuesta correcta, un gráfico asociado, ...
Respuesta, asociada a un usuario concreto y una pregunta concreta, guardando el resultado (acierto/fallo), etc.
Creación del proyecto y la aplicación
Lo primero es crear el proyecto: django-admin.py startproject Trivial
Ajustamos algunos parámetros en settings.py y urls.py. Habilitaremos la interfaz administrativa , el directorio desde el que se sirven los contenidos estáticos y algunos ajustes más.
Cuando queramos pasar a producción, sólo tendremos que eliminar la última entrada en urls.py
y editar MEDIA_URL en settings.py.
También tenemos que crear la base de datos sqlite (comando sqlite data/datos.db).
Ahora, desde el directorio Trivial (directorio raíz) creamos la aplicación propiamente dicha (juego): python manage.py startapp juego.
Definiendo los modelos
Editamos el fichero juego/models.py para definir nuestros objetos. Las clases que representan modelos deben heredar de la clase Model y
siguen una sintaxis muy sencilla e intuitiva.
Django incorpora en el paquete django.contrib.auth todo un sistema de autentificación y gestión de usuarios, así que no vamos a reinventar la rueda y utilizaremos este sistema .
Estos son nuestros modelos:
from django.db import models from django.contrib.auth.models import User
class Usuario(User): def __str__(self): return self.username
class Admin:
pass
class Categoria(models.Model): nombre = models.CharField("Categoría", maxlength=200)
me="Categoría la que pertenece") titulo = models.CharField("Título", maxlength=200) texto = models.TextField("Texto de la pregunta") respuesta_1 = models.CharField(maxlength=200)
Como decíamos antes, "mejor explícito que implícito". Definimos un método __str__ en todas las clases para tener una descripción "humana" de cada objeto, tanto a la hora de desarrollar como de gestionar en la interfaz administrativa. La clase anidada Admin sirve para que la clase madre aparezca en la interfaz administrativa.
La clase Usuario hereda directamente de la clase User de Django (django.contrib.auth.models.User).
Por último, haremos que Django sincronice la información que tiene de los modelos con el sistema relacional (vamos, que cree las tablas necesarias): python manage.py syncdb Este comando también creará las tablas necesarias para la aplicación administrativa y el sistema de gestión de usuarios (de hecho nos pedirá los datos necesarios para crear un "superusuario"). Si arrancamos el servidor y apuntamos nuestro navegador a http://localhost:8000/admin/ veremos en marcha la interfaz de administración:
Lo primero que hemos hecho ha sido crear un grupo (Concursantes) y asignarle el permiso de "crear objetos del tipo Respuesta". Después creamos unos cuantos usuarios y les hacemos miembros del grupo. Ya tenemos un sistema de control de acceso, permisos bastante granulares (estos usuarios sólo podrán crear objetos del tipo Respuesta, pero no modificarlos o borrarlos) sin escribir nada de código.
Siguente: implementando la autentificación
El siguiente paso es relativamente sencillo si utilizamos las facilidades que Django nos proporciona. El decorador @login_required en el paquete django.contrib.auth.decorators template de validación (registration/login.html por defecto): funciona de la siguiente manera : si el usuario no está autentificado, redirige a una plantilla o
Si está autentificado, la función "decorada" ( index en este caso) se ejecuta normalmente.
La primera pantalla que queremos que el usuario autenfificado vea es un listado de preguntas clasificado por categorías. Éste sería nuestro "index.html", pero, como hemos dicho, queremos que el usuario se valide antes. Veamos cómo hacerlo.
En urls.py añadimos una entrada para "mapear" la dirección "/" (raíz del sitio) a la función
) ¿Qué hace este index? Recoge todas las categorías, preguntas
y respuestas del usuario validado y se las "pasa" a una plantilla o template llamada "index.html". También le pasa los datos del usuario (request.user). Como hemos especificado que hay un login previo, podemos estar seguros de que esta variable "usuario" tiene datos correctos.
{% extends "base.html" %}
{% block cuerpo %}
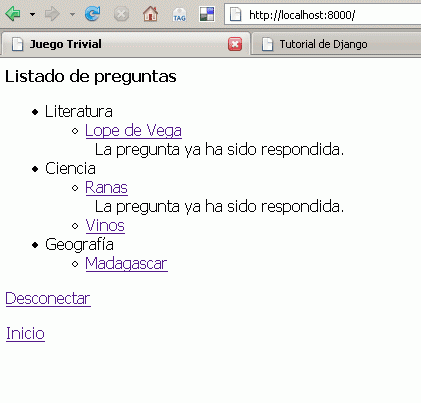
Listado de preguntas
{% if categorias %} {% regroup preguntas by categoria as agrupado %}
en este template comprobamos si hay categorías {% if categorias %} y mostramos en forma de listas anidadas todas las preguntas de cada categoría con la etiqueta {% regroup preguntas by categoria as agrupado %} y lo que sigue. Para cada pregunta comprobamos si tiene una respuesta asociada:
{% for r in respuestas %} {% ifequal item r.pregunta %} La pregunta ya ha sido respondida. {% endifequal %} {% endfor %}
En este template también estamos utilizando una característica muy útil: la herencia de plantillas. En una plantilla aparte ( base.html) definimos un esqueleto con unos bloques de
contenido que cada una de las plantillas "hijas" se encarga de completar con {% block loquesea %}
Así quedaría nuestra pantalla inicial:
Formulario de preguntas
Cuando el usuario sigue el enlace ({{ item.titulo }}) que presenta cada pregunta en la plantilla index.html se le dirige a la página que llamaremos "ficha de pregunta". Estas son las modificaciones que hemos introducido:
A la función pregunta le llegan dos argumentos: request e id, tal y como se define en urls.py. Lo primero que hacemos es buscar la pregunta correspondiente (pregunta = Pregunta.objects.get(id=id)) y luego buscamos la posible respuesta que haya podido hacer el usuario en una anterior visita (respuesta = Respuesta.objects.get(pregunta=id, usuario=request.user)). Si no hay respuestas capturamos la excepción, asignamos None a la respuesta y seguimos.
Finalmente, ésta es la plantilla que muestra los datos de una pregunta, pregunta.html:
Nos encontramos en esta plantilla con una variable (texto_error) que no hemos asignado desde la función pregunta. Esta variable puede tener un valor cuando esta plantilla es invocada desde otra función definida en views.py (respuesta). Lo veremos un poco más adelante.
Lo primero que comprobamos es si esta pregunta ya ha sido respondida. Si es así, la variable respuesta tendrá un valor distinto a None. En este caso informamos al usuario del resultado y el tiempo empleado en resolver la pregunta.
si no hay respuesta, generamos un formulario con las posibles respuestas y dos campos ocultos con el id de la pregunta y una marca de tiempo. El formulario apunta a la url /responder/
Respondiendo a la pregunta
De nuevo, añadimos una regla al fichero urls.py para procesar las respuestas de los usuarios. El fichero quedaría así (versión final):
Primero localizamos la pregunta (nos llega el id en la variable POST 'pregunta'). Después comprobamos que han pulsado uno de los "radiobutton" de respuesta (request.POST['respuesta']). Si no han respondido, redirigimos de nuevo a la página de pregunta pasando un mensaje de error.
Si han respondido, creamos un objeto Respuesta asociado a la pregunta y al usuario. También asignamos a esta respuesta el tiempo que se ha tardado en resolver la pregunta y el resultado. Después, redirigimos a la plantilla 'respuesta.html' pasando el objeto pregunta, el objeto respuesta recién creado y la opción que habían seleccionado.
Sencillo, simplemente mostramos los datos del objeto respuesta, la pregunta asociada y lo que el usuario respondió.
Conclusiones
Hemos hecho una aplicación web muy básica y sencilla, pero demuestra que muchas tareas complicadas y/o tediosas de implementar nos la proporciona la herramienta Django. La interfaz administrativa y el sistema de autentificación nos han salido "gratis". Probablemente, la implementación de estas dos funcionalidades nos hubiesen llevado bastante tiempo.
Observamos también la extrema sencillez en el desarrollo: con cuatro elementos con unas funciones muy concretas (urls, modelos, vistas y plantillas) tenemos perfectamente separadas la lógica, los datos y la presentación. Compárese esta simplicidad con la típica aplicación J2EE, por sencilla que sea. No hay color. Que las soluciones basadas en J2EE sean más "potentes", escalables, robustas, etc. no lo voy a negar. Pero, ¿acaso se necesita siempre esa "potencia"?.
No hemos desarrollado una aplicación similar con Rails, por lo que no sería muy justo decir que Django es más fácil o mejor. Lo que si que podemos decir, por lo que hemos visto y leído es que Django aporta varias características que ahorran mucho trabajo, en este caso la interfaz administrativa y el sistema de autentificación